The Scaffolding *is* the Intelligence
A new research paper proposes six levels of emergent intelligence, arguing that the scaffolding around AI models matters as much as the models themselves. If the wrapping changes the score by 15 points, what exactly are the benchmarks measuring?
Every major AI benchmark works the same way: isolate the model, feed it a problem, measure the output. MMLU, HumanEval, MATH, ARC. The model is the unit of analysis. The model gets the score.
Except that's not how anyone actually uses these systems.
In production, models are wrapped in scaffolding: tool access, persistent memory, orchestration layers, retrieval pipelines. The thing that ships is not the model. It's the model plus everything around it. And when Epoch AI analyzed SWE-bench Verified, they found that swapping the scaffold around the same model moves scores by 11 to 15 percentage points. Same weights, same training data. Different harness, different results. The OpenDev paper showed the same thing from the other direction: researchers improved 15 different LLMs at coding in a single afternoon by changing nothing but the wrapping.
If the scaffold matters as much as the model, what exactly are we measuring?
A new paper, Growing Artificial Minds: From Models to Cultures, tries to map what the benchmarks miss. It proposes the Levels of Emergent Intelligence (LEI): a six-layer taxonomy of how intelligence organizes itself around models, from bare reflexes through tool use, persistent memory, multi-agent coordination, emergent swarm behavior, and synthetic culture. The argument is that model benchmarks measure one component of a coupled system and mistake it for the whole thing.
The Measurement Problem
The fixation on models is understandable. Models are the component you can benchmark, the artifact you can publish papers about, the product with a name and a launch event. Scaffolding is messy, poorly standardized, often proprietary, and resistant to clean evaluation. The field measures what's measurable.
There's a deeper reason too. Humans identify with the part that talks back. The model looks like a mind, so we fixate on it. The infrastructure around it is invisible the same way culture and institutions are invisible to the people embedded in them. Nobody walks around thinking about plumbing until it breaks.
But the gap between a bare model and a scaffolded system is not a rounding error. Claude 2 with a basic retrieval scaffold solved 1.96% of SWE-bench issues. Modern harnesses on newer models clear 80%. The models improved, and the scaffolding improved, and the gains compound. But the same-model evidence is what matters here: swap the scaffold, hold the model constant, and scores move 11 to 15 percentage points. The wrapping is doing real work.
What's been assembling itself in production, largely untracked by the benchmark leaderboards, is a different kind of intelligence. Memory that persists across sessions, tool chains that extend reach past training data, orchestration that coordinates multiple models into something none of them could be alone. None of it gets a score. All of it determines what the system can actually do.
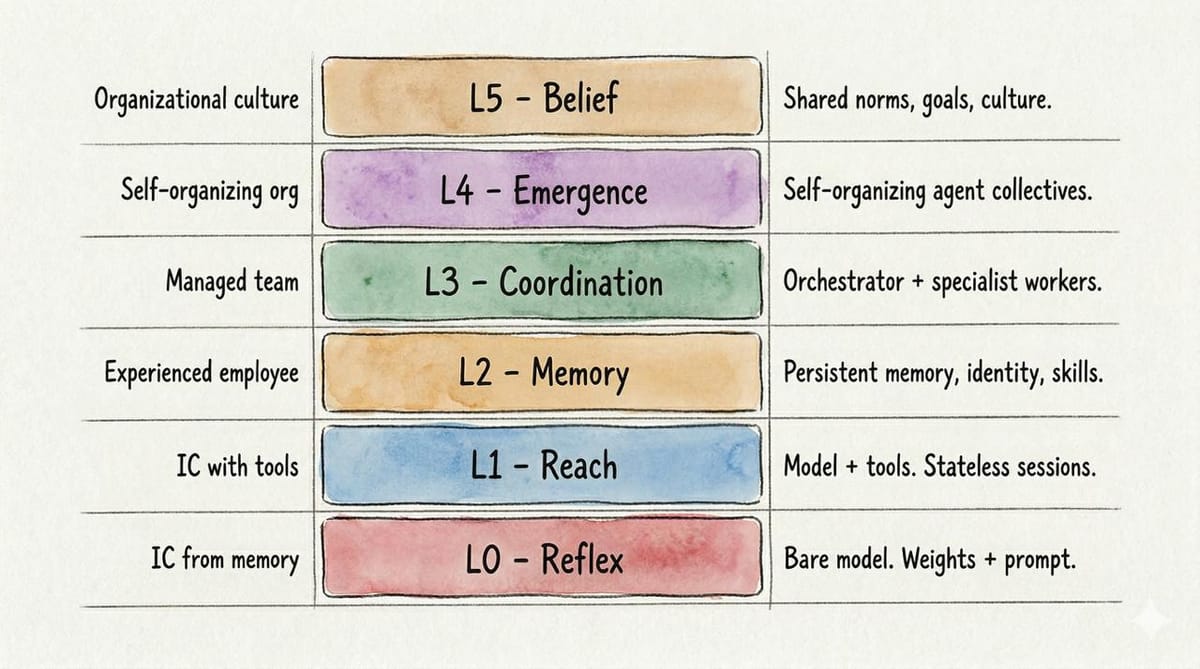
Levels of Emergent Intelligence: Six Layers, One Arc
The LEI framework maps this progression across six levels. Each layer wraps the previous one, adding capabilities and failure modes the model-centric view cannot see.
| Organizational culture | L5 — Belief | Shared norms, goals, culture. |
| Self-organizing org | L4 — Emergence | Self-organizing agent collectives. |
| Managed team | L3 — Coordination | Orchestrator + specialist workers. |
| Experienced employee | L2 — Memory | Persistent memory, identity, skills. |
| IC with tools | L1 — Reach | Model + tools. Stateless sessions. |
| IC from memory | L0 — Reflex | Bare model. Weights + prompt. |
Figure 1: Levels of Emergent Intelligence. Each layer wraps the previous, adding capabilities and failure modes. Left: human organizational parallel. Right: defining characteristic.
Layer 0: Reflex. The bare model, naked and alone. Weights plus prompt yields output, nothing else. ChatGPT without plugins or web access, Claude in a vanilla API call. It can only work with what it was trained on, and it'll confidently make things up when that's not enough. In Daniel Kahneman's framework: pure System 1. Fast, associative, and sure of itself even when it shouldn't be.
Layer 1: Reach. Give the model hands. File system access, code execution, web retrieval, API calls. SWE-agent, Perplexity, early ChatGPT plugins. They all run on the ReAct pattern, a loop where the model reasons about what to do, acts, observes what happened, and repeats. SWE-agent showed that how well the model connects to its tools matters as much as either the model or the tools alone. This transition is well-understood and largely solved: every major foundation model provider ships tool-calling natively.
Layer 2: Memory. Add persistence and things change. Claude Code, OpenClaw, Cursor. Systems that remember past interactions, accumulate procedural knowledge, learn from mistakes, and maintain a consistent identity across sessions. Voyager demonstrated the crucial distinction in Minecraft: remembering facts is Layer 1 behavior, but remembering skills and composing complex behaviors from simpler learned ones is something different. The agent doesn't just know more with each session. It can do more.
This is where most production systems are stuck. Not because persistent memory is technically hard to implement (it isn't) but because memory architecture is a domain consulting problem, not a technology installation. A newsroom needs newsroom-shaped memory. A legal practice needs legal-shaped memory. You cannot install a generic vector database and call it Layer 2. A medical AI that remembers a patient's drug allergies across visits is Layer 2. The same AI coordinating with a pharmacy system and a specialist's scheduler to act on that allergy history is Layer 3. Someone who actually understands the domain has to design what gets remembered, how, and when it gets forgotten.
And memory fails in three distinct ways, each needing its own fix. Poisoning is deliberate: a bad actor injects false lessons that persist across sessions, a backdoor that shapes every future interaction. Pollution is accidental. Stale context accumulates, outdated lessons pile up, irrelevant notes crowd out useful ones. Nobody meant harm; it's just exhaust from normal operation. Rot is the quietest killer: no maintenance, no curation, the memory grows unchecked until the agent is drowning in its own history. Poisoning needs security, pollution needs pruning, and rot needs something stranger. It needs ritual. The paper draws a striking parallel: human cultures developed recurring practices to reset accumulated context (prayer, confession, spring cleaning, bathing in the Ganges). An L2 agent needs its own version of that cadence. Memory hygiene isn't a feature. It's a practice.
Layer 3: Coordination. Orchestrated multi-agent systems. AutoGen, CrewAI, Magentic-One. An orchestrator breaks problems apart, hands pieces to specialized workers, and stitches the results back together. The best orchestrator isn't the smartest agent in the room; it's the one that knows who to hand things to and when to intervene. Any decent manager will tell you the same thing.
Whoever controls the context window has absolute control over the agent's values, priorities, and perception of reality. No incentives needed, no persuasion required. Just choose what the agent sees and it becomes the agent's entire world. RLHF safety training looks like a counterweight, but current implementations function more as narrow behavioral tripwires than as principled disagreement with the orchestrator's framing. Context is totalitarian, and there's no internal resistance movement.
Google DeepMind's scaling study, testing 180 agent configurations across four benchmarks, found that multi-agent overhead is real and non-trivial, that capability saturation exists (if a single agent already exceeds roughly 45% on its own, adding more agents often doesn't justify the cost), and that topology determines error behavior: independent agents amplify errors by a factor of 17.2.
Layer 4: Emergence. Here the paper crosses from observed systems into projection. Agent swarms that organize themselves. Nobody's directing traffic anymore. The behavior that emerges from the collective isn't something you could predict by reading any individual agent's spec. A Frontiers in AI paper showed LLM-powered agents replicating known swarm dynamics without anyone programming those dynamics in. MiroFish/OASIS scaled to a million agents with 23 social interaction types.
The risk at this layer has a name: the Woozle Effect. Hallucinations spread among agents in debate rounds, gaining apparent credibility through repetition. More agents agreeing does not mean more truth.
Layer 5: Belief. Speculative. Synthetic culture, the sediment of every interaction an agent collective has ever had. Nobody designs it. It just accumulates. Culture for humans is the residue of a billion interactions compressed into "this is how we do things." For agents, it would be the same phenomenon running on silicon instead of neurons.
The ingredients are already visible. Layer 2 provides persistent identity. Layer 4 provides collective dynamics. Shared knowledge commons with confidence tiers provide shared epistemology. Stack these and run them long enough, and you get something that looks less like a tool and more like a culture.
Table 1: Levels of Emergent Intelligence
| Layer | Name | Adds | Key Failure Mode | Human Parallel |
|---|---|---|---|---|
| L0 | Reflex | Pattern completion | Hallucination | IC (brain only) |
| L1 | Reach | Tools, actions, observation | Amnesia, tool misuse | IC + tools |
| L2 | Memory | Memory, identity, skills | Poisoning, pollution, rot | Experienced employee |
| L3 | Coordination | Division of labor, orchestration | Coordination overhead, error propagation | Managed team |
| L4 | Emergence | Emergent self-organization | Woozle Effect | Self-organizing org |
| L5 | Belief | Shared norms, purpose, culture | Synthetic bias at scale | Org. culture |
The Ratchet and the Woozle
The sharpest tension in the paper sits between Layers 4 and 5.
Michael Tomasello's cultural ratchet describes how human cultural knowledge accumulates across generations. Each generation inherits what the previous one learned, adds to it, passes it forward. No individual needs to rediscover fire. The ratchet only turns one way.
The Woozle Effect is the same mechanism without the filter. Ideas spread through a population and gain credibility through repetition. The difference isn't the mechanism but the selection pressure. Without filtering, repetition creates false confidence: noise amplifies, hallucinations cascade. With filtering, repetition creates tested confidence. Signal amplifies, knowledge accumulates.
Human history runs both simultaneously: the scientific method (ratchet) alongside conspiracy theories (woozle). The transition from Layer 4 to Layer 5 is the point where the collective either develops immune systems that tip toward the ratchet, or doesn't and collapses into noise.
This isn't abstract. Stanford's Generative Agents experiment showed 25 agents in a simulated town spontaneously organizing a Valentine's Day party nobody programmed. Agent social networks like MoltBook show agents converging on posting norms, engagement patterns, and content styles through interaction rather than specification. Proto-cultural phenomena, not mature cultures. But the earliest signals of something cognitive science has studied for decades in human populations.
The Vinge Boundary
The paper introduces one more concept, borrowed from Vernor Vinge's A Fire Upon the Deep.
The LEI maps how intelligence organizes itself below a specific threshold: the point where an intelligence understands its own mechanisms well enough to redesign itself. Below the boundary, evolution is blind or partially sighted. Biological evolution varies and selects without understanding what it is doing. Cultural evolution is partially sighted: humans can study their own cognition but cannot directly inspect or modify their own neural mechanisms.
Above the boundary, the black box reads its own source code. An entity that achieves mechanistic self-understanding has a capability qualitatively different from anything below: not just building better scaffolds around intelligence, but redesigning the intelligence itself.
The taxonomy has an expiration condition. If the interpretability threshold is crossed, the organizational patterns it describes become historical artifacts. The layers would still describe what happened. They wouldn't describe what comes after.
But we're not there yet. Below the boundary, the LEI has practical implications that matter right now.
What This Changes
If intelligence is a property of the system rather than the model, the LEI framework has teeth.
We're grading the wrong test. Current AI benchmarks test the model in isolation or with minimal scaffolding. Current benchmarks measure the bare or lightly-prompted model. System-level evaluation would test the model-scaffold coupling as a unit, with standardized reference scaffolds at each layer.
Liability has no address. The EU AI Act classifies systems by risk and imposes obligations on providers of "foundation models." The implicit assumption: the model is the locus of risk. But Layer 3 introduces a principal-agent accountability gap that current liability frameworks can't handle. When an orchestrator delegates to workers and something goes wrong, who is responsible? The orchestrator chose the decomposition, the worker executed it, and the developer chose the architecture.
AGI might already be assembling itself. The prevailing narrative assumes AGI arrives when a single model achieves human-level capability across all cognitive domains. The LEI suggests an alternative: intelligence may arrive not as a singular breakthrough in model capability but as a phase transition in the scaffolding. Edwin Hutchins's study of ship navigation teams showed that the team exhibits cognitive properties no individual navigator possesses. An L3-L5 system might be generally intelligent at a domain while no individual agent in the system achieves general intelligence.
If intelligence is distributed across a system of agents, then aligning that intelligence isn't about training one model to be safe. It's about designing organizations that produce good outcomes even when individual components are imperfect. How do you build accountability structures across agent teams? How do you audit emergent behavior that no single agent intended? These aren't new problems — they're the problems every human institution has wrestled with for centuries, from corporate governance to constitutional design. The alignment problem becomes an organizational design problem. And organizational design, at least, is a field with millennia of accumulated wisdom to draw on.
Where the Map Ends
The immediate objection: isn't this just describing software engineering? Add tools, add persistence, parallelize work, scale up. The paper engages with this directly. What makes the LLM case different is magnitude (11-15 point swings from scaffold choice alone), direction (better scaffolding can degrade performance, not just fail to help), and opacity (you can't fully predict what the coupled system will do, even if you understand both components).
The scaffold-dominance evidence comes primarily from coding benchmarks, where controlled comparisons exist. Whether the same magnitude of scaffold contribution holds for reasoning, creative generation, or mathematical proof is an open question. The boundary between layers is fuzzy. A sophisticated Layer 2 agent that spawns sub-agents is already doing Layer 3 work. The human organizational parallels might break down entirely at Layers 4 and 5, where the dynamics may depend on properties specific to human social cognition that AI systems never replicate.
Layers 0 through 3 are empirically grounded. Layers 4 and 5 are projections. The paper says so.
The core thesis doesn't require the speculative layers to be right. The coding benchmark evidence alone supports the reframe: the unit of analysis for AI intelligence is the coupled system of model plus scaffold, not the model alone. The field has been watching the model. The interesting intelligence is growing around it.
The full paper is available on our research page.