The Four Floors
AI compresses the path to the decision. The decision is still someone’s problem.
This is the eighth article in "The Shape of the Next Decade," a series on how AI reshapes work, institutions, and ordinary life. Part seven: The Rehearsal Problem. The people in this piece are representative scenarios, not reported cases.
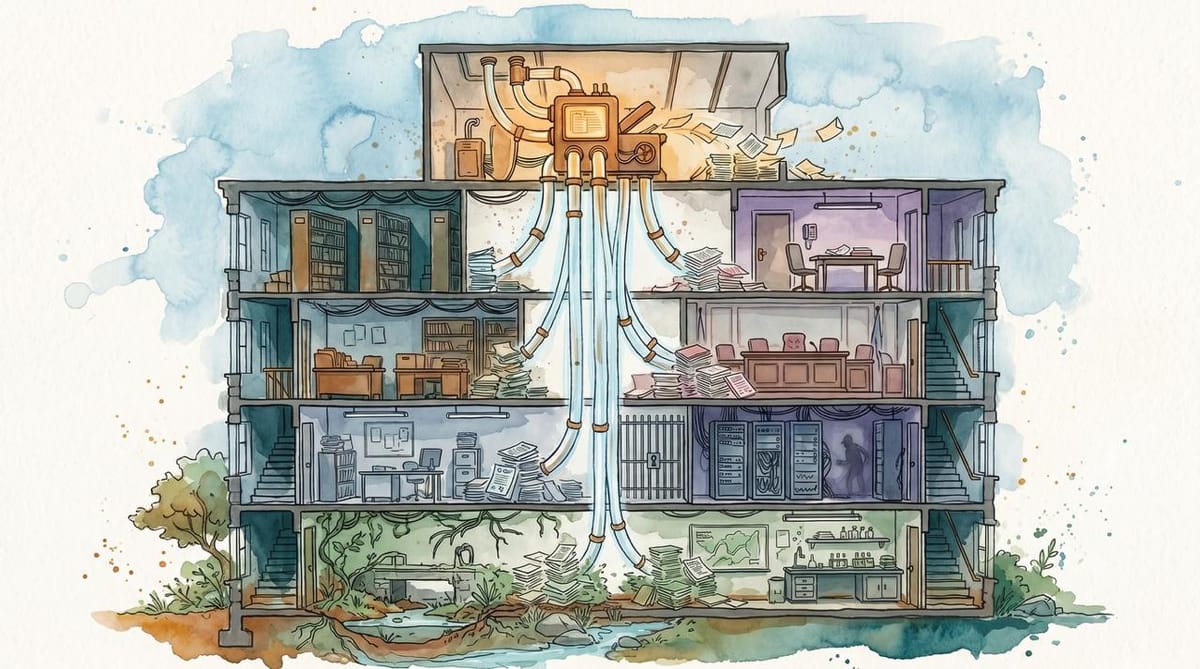
Renata’s project folder exceeds eleven hundred pages. Maps, traffic studies, wetlands surveys, consultant memos, public comments, agency letters, mitigation tables, revised drawings, and PDFs with filenames that seem designed to punish whoever opens them next. Before anyone on the planning commission can decide whether the development should move, someone has to make the record legible. The comments need reconciling, the missing studies need flagging, the mitigation table has to match the version filed six weeks ago, and someone still has to draft the staff report that a roomful of people will pretend to have read.
The model did all of it in an afternoon. Renata has the cleanest project record of her career sitting on her screen, and the decision in front of her is exactly as hard as it was three weeks ago.
The record cleanup matters because permitting delay is often a coordination problem, not one dramatic missing answer. Federal data shows just 39% of environmental impact statements finish inside the two-year deadline Congress set in 2023; nearly a quarter take more than five years, and some run past a decade. When the Council on Environmental Quality looked at why, the first reason it named was coordination: large projects span agencies and jurisdictions and stakeholders, and somebody has to drag all of it into one legible place before anyone can act.
That part is exactly what AI is good at. Give a model the packet and it summarizes the comments, separates the duplicate objections from the new ones, checks the record for the study that should be there and isn't, builds the timeline, and drafts the first version of the report. The work is mundane, which is exactly why it is so compressible. A document says one thing, a second document says something related, a regulation asks whether the first two have been reconciled, and a person who used to spend a week dragging the answer into view can now have it before lunch.
This is the AI productivity story most people will actually live, the one that never makes a keynote. A lot of institutional work is not judgment. It is assembly, routing, reconciliation, checking whether the same fact appears under four names in three systems. If AI did nothing but lift that weight off permitting offices, hospital billing departments, compliance desks, and courts, the gain would be enormous. The previous piece in this series, The Rehearsal Problem, described this as the coordination layer: the routing, reconciliation, and handoff work where AI reaches the most people first.
But the clean packet is not the decision. The model can organize the record, but it cannot decide how much weight to give the wetlands survey, the neighbor whose basement flooded last year, or the developer’s promise to fix the drainage. Those are judgment calls the county has to make in public, with reasons it can defend afterward. Summarizing the record and owning the decision are different acts, and only one of them got faster.
What AI stops at, though, is not always the same kind of obstacle. It can compress the work around a decision and still leave the hard part untouched. Sometimes the remaining floor is reality: a molecule has to work, a bridge has to hold, an adversary gets to fight back. Sometimes the floor is answerability: a person or institution has to own the call. They look alike from the queue, and telling them apart is about to become one of the more useful skills a person can have.
Floors made of reality
Consider a drug. A pharmaceutical team can use AI to assemble much of a regulatory submission: reconcile trial data, draft the toxicology narrative, format results to the agency’s specification, and flag the missing assay before a reviewer sends the application back. That paperwork is vast, but it is still paperwork, which makes it compressible. For many drugs, the FDA’s review of a finished application has fallen to under a year.
But a new medicine still takes ten to fifteen years to reach a pharmacy, and clinical trials take six to ten of those years. AI can help around the trial: draft protocols, screen patients, coordinate sites, clean data, and keep the paperwork from swallowing the science. What it cannot compress, at least while trials still work the way they do now, is the time a drug has to spend inside real bodies before anyone knows whether it works and whether it hurts people. No amount of generated language makes a liver process a compound faster or a tumor shrink on schedule. The model can shorten the path to the test. It cannot make the test instantaneous.
This is a floor made of reality. The compound clears the trial or it does not. The result may be messy, slow, and expensive to get, but the validator sits outside the language model. Bodies respond, side effects appear, endpoints are met or missed. You can fight over trial design and interpretation, but the drug still has to survive contact with the thing being measured.
Security looks similar at first because it also has an external test. A vulnerability is real if the exploit works, and a patch is real if the exploit stops working. That makes the field unusually friendly to AI: models can search code, generate candidate exploits, and surface bugs that older tools and human reviewers missed. In Anthropic’s Glasswing work, an unreleased model found thousands of zero-day vulnerabilities across major operating systems and browsers, including one OpenBSD bug that had survived twenty-seven years of scrutiny and one FFmpeg bug in a line of code automated tools had already passed over millions of times.
The bottleneck moves after discovery. Each finding still has to be verified, disclosed to the right maintainers, turned into a patch, tested against the systems it might break, and deployed into environments that cannot simply be taken offline. A model can make the candidate list longer very quickly, but every candidate still has to become a fix that survives contact with the real system.
Security differs from the drug case because the floor pushes back on purpose. A bridge does not change its strategy because you inspected it; a molecule does not mutate to defeat your assay. An attacker does. Once a detector exists, someone can study it, poison its inputs, route around the control, or wait until the alerts become background noise. More generation helps, but the hard part is not just finding more things to fix. It is defending a system against people who adapt to the defense.
Both are floors AI can press hard against and sometimes win, but the outcome depends on what happens outside the model, not on how quickly the model can produce the next step.
Floors made of answerability
Now go back to Renata's hearing, because the second kind of floor is not made of reality at all.
Much of what a public agency does should be automated. Forms should route themselves. Notices should go out on time. Completeness checks, deadline tracking, and duplicate reviews should not eat whole afternoons. Clearing that friction can be good government. The mistake is trying to treat the moment of answerability as another piece of friction to clear.
Michigan made exactly that mistake. In 2013 the state turned unemployment fraud determinations over to an automated system called MiDAS and let it run with little human oversight. When the state auditor later reviewed a sample of the cases it had decided, 93% of the fraud findings were wrong. The system had accused as many as 40,000 people, seized tax refunds, and garnished wages, and it had done so with the confident output of a process that looked like adjudication and had quietly removed the part where a person was answerable for the call. Australia’s Robodebt scheme followed the same pattern. The government used automated income averaging to raise welfare debts at scale, pursuing roughly 470,000 people before a royal commission called the program “crude, cruel and unlawful.”
A fraud finding, a benefits decision, an asylum ruling, a custody order: what makes one of these valid is not that it looks correct, but that an institution stood behind it and can be made to answer for it when it is wrong. Generate the output and strip that part out, and you are left with a document that wears the same name but lacks the authority it claims.
Contracts sit near the same floor, though they are one step away from the state. AI can redline an agreement, compare it against the playbook, flag an unusual indemnity clause, and draft fallback language for the force majeure section. Legal teams are right to want all of that. But a contract is not only language. It is a record of who is making a promise, what happens if the promise breaks, and which institution can enforce the promise afterward. AI can improve the clause. It cannot, by itself, supply the authority behind the signature or the trust that makes either side believe the other will behave when the clause runs out.
These floors fail differently from a drug trial or cybersecurity vulnerability. There is no trial you can run on a verdict to find out whether it was legitimate, no external test that certifies a custody decision the way a lab certifies a compound. The only thing that validates the decision is a human or an institution being answerable for it, which means automating the output does not get you a faster valid decision. It gets you a faster output with the validity quietly removed.
From the outside, both bottlenecks can look the same: AI moved the process quickly, then reached a floor outside the model. But the reason is different. A drug trial stops at evidence the model cannot generate. A verdict stops at authority the model cannot hold. One needs the world to answer. The other needs someone to answer.
The floor is not always noble
The danger is that answerability can become an excuse for protecting slow processes that mostly serve the people who benefit from them. Every bottleneck has someone ready to call it judgment, and every protected toll booth can learn to describe itself as care. Most claims that a task must stay human turn out to be wrong. Scribes, navigators, switchboard operators, film projectionists, and a long line of others were defended on principle and automated anyway, and the people who defended them mostly looked, in hindsight, like they were guarding a toll booth.
So the test cannot be whether a human used to do the work. That test protects far too much, and history keeps overruling it. The better question is narrower: what would actually make the result valid?
If there is something outside the language model that can settle it, the floor is probably the reality kind, and it may even be friction dressed up as judgment. Sometimes the check is a unit test, a physical measurement, a clinical trial, a proof, or an adversary that fails to break your system. When a check like that exists, AI can compress the work up to it. Medical imaging worked this way. The scan had an answer outside the reader: a tumor was there or it was not, a fracture was visible or it was not. Once machines got good enough at finding that answer, part of the radiologist’s work became easier to automate.
Some decisions are valid only because an accountable person or institution stands behind them. When automation reaches that point, it has crossed from speeding up the work around a decision into trying to supply the authority for the decision itself. The difficult line is between answerability that is genuinely necessary and process that was just built badly. MiDAS and Robodebt were catastrophes of execution, so they do not settle every question about automated decision systems. But they show the failure mode clearly: an incomplete file can be fixed with better process. An unowned decision cannot.
Faster up to what
So when the next AI tool promises to make permitting, drug review, security triage, or contract work ten times faster, the speed is usually real, and the better questions are the ones underneath it. Which layer did it actually compress, and what is left standing once the compression is done?
Four floors keep showing up. The first is physical or biological reality: the drug has to work in bodies, the bridge has to hold, the measurement has to come back from the world. The second is adversarial reality: the system has to hold against people who learn, route around controls, and attack the defense itself. The third is institutional authority: the verdict, benefit decision, permit approval, or custody order has to belong to someone who can be challenged and made to answer. The fourth is relational trust: the contract may be drafted perfectly, but the deal still depends on whether the people behind the signatures believe the other side will behave when the document runs out.
AI can compress the work leading up to all four. It can prepare the submission, find the bug, summarize the record, redline the clause. But the floor tells you what kind of limit remains: reality, opposition, authority, or trust.
1. Physical or biological reality — the result depends on something the model cannot simulate. A body, a material, a measurement, or a physical process has to answer.
2. Adversarial reality — the result depends on holding against an opponent who adapts. Detection, defense, and control face people who learn, route around, and fight back.
3. Institutional authority — the result is only valid because an accountable person or institution stands behind it and can be challenged when it is wrong.
4. Relational trust — the result depends on whether the parties involved believe the other side will follow through beyond what the document requires.
Most real workflows hit more than one floor. A drug faces biological reality in the trial, institutional authority at approval, and relational trust when doctors and patients decide whether to use it. A security system faces adversarial reality first, then institutional authority when someone has to decide which risks to accept and which patches to ship. The useful question is not whether AI made the process faster. It is which floor still controls the outcome.
Editor’s note: This is the eighth piece in The Shape of the Next Decade, and it marks a turn. The earlier installments followed AI into the work it handles most easily: the paperwork, the routing, the coordination that buries institutions before anyone gets to make a decision. This piece asks what is still standing after that work is done.
The four floors are a starting test, not the final map. Some of them may turn out to be less solid than they look. Others may prove harder to name than this piece makes them seem. The series will keep pressing on the distinction between a floor that protects something real and a floor that just protects itself.
For now, the useful question is the one the piece ends on. When AI makes something faster, ask what floor it reached, and whether what remains is a genuine limit or just an old bottleneck in a better suit.
Download the one-page field guide
If you want the short version of this frame, I put together a printable one-page reference for the Four Floors: physical reality, adversarial reality, institutional authority, and relational trust.

